Fast PDF Conversions in PDFix Desktop
Use the ![]() Conversion Panel to export PDFs to formats like HTML or JSON for structured data reuse.
Conversion Panel to export PDFs to formats like HTML or JSON for structured data reuse.
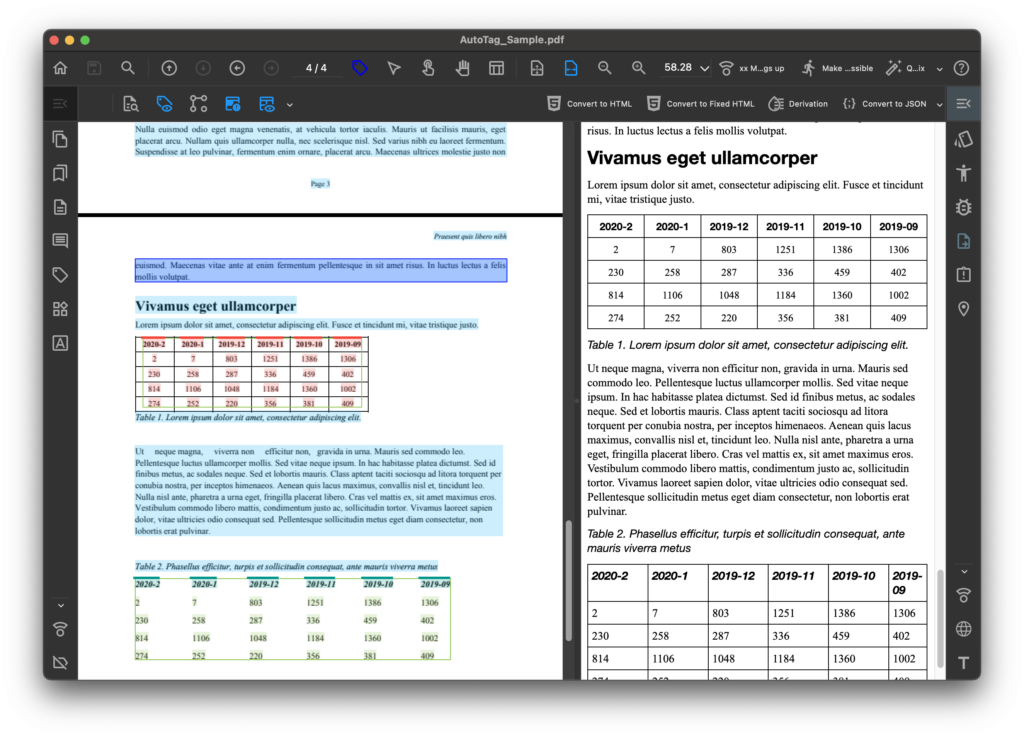
The screenshot below shows PDFix Desktop in action: the original PDF and the converted HTML output.
Basic Conversion Actions
Basic Conversion Actions let you transform PDFs to HTML or export data to JSON.
PDF to HTML Conversion Methods in PDFix
 Tagged PDF to Responsive HTML
Tagged PDF to Responsive HTML
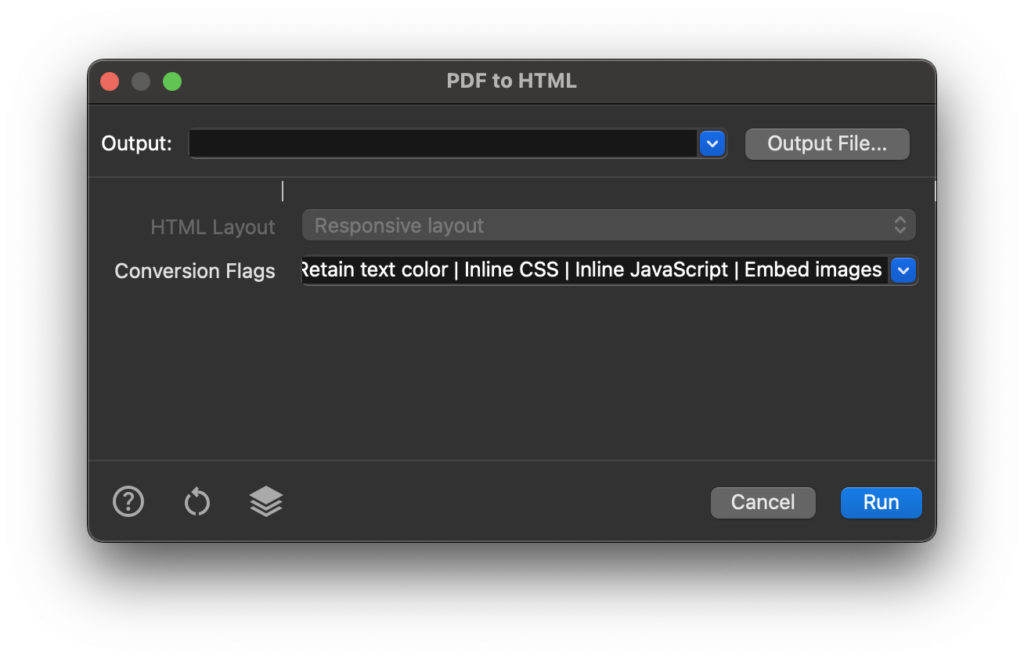
PDFix uses the Derivation Algorithm to convert tagged PDFs into responsive HTML, automatically preserving the document structure. It automatically analyzes PDF tags to generate clean, mobile-friendly HTML that maintains your original layout while adapting seamlessly to all screen sizes.
 Untagged PDF to HTML
Untagged PDF to HTML
Most PDFs lack proper structure and tags. That’s why we developed our AI-powered Layout Recognition Tool – it automatically analyzes and structures untagged PDFs, enabling seamless conversion to clean, well-formatted HTML.
Convert to Fixed HTML
This conversion produces ![]() Fixed HTML that exactly preserves your original PDF formatting and page structure. While this option maintains precise visual fidelity, we generally recommend responsive HTML conversion for modern applications, as it automatically adapts your content to display properly on all devices while maintaining document integrity.
Fixed HTML that exactly preserves your original PDF formatting and page structure. While this option maintains precise visual fidelity, we generally recommend responsive HTML conversion for modern applications, as it automatically adapts your content to display properly on all devices while maintaining document integrity.
Data Extraction
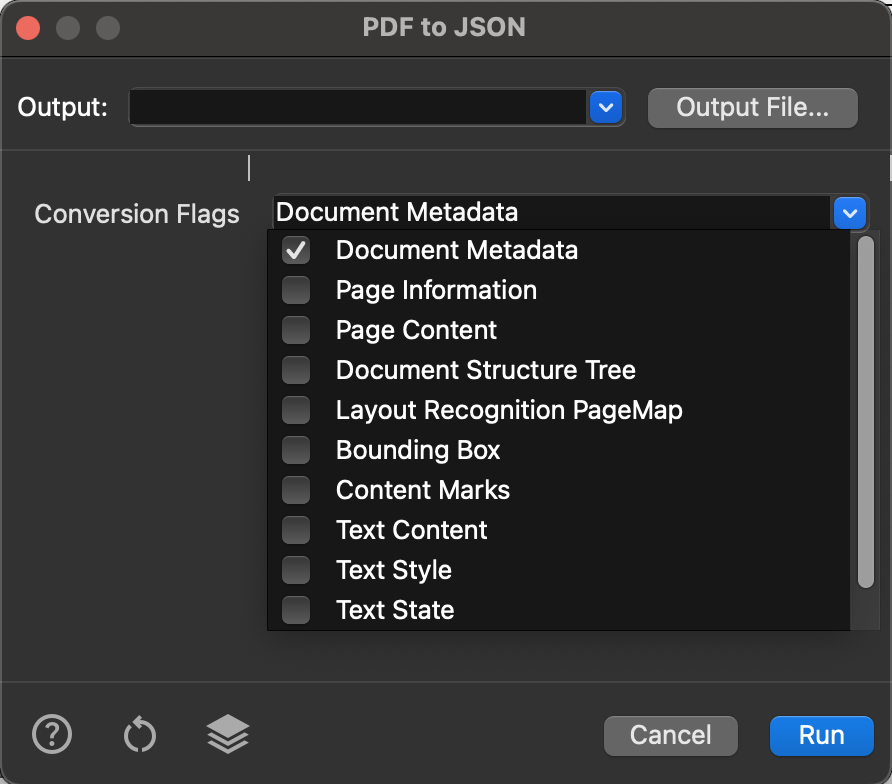
To extract data, use the ![]() Convert to JSON action to export data according to your specified requirements.
Convert to JSON action to export data according to your specified requirements.
Export Selection to HTML
In PDFix Desktop, you can convert only your current selection – a specific part of your PDF – to HTML. This is perfect for extracting single tables or sections. Here’s how:
- Select your Data
- Use either the Default Tool or Object Tool.
- Select the desired objects or area.
- Right-click and choose Convert to HTML from the Menu.

Copy with Formatting
![]() Copy with Formatting performs the same function as Export Selection to HTML but copies the output directly to your clipboard. You can then paste the formatted data into applications like Excel or Google Docs, preserving all original structures including tables, lists, formatting, and more.
Copy with Formatting performs the same function as Export Selection to HTML but copies the output directly to your clipboard. You can then paste the formatted data into applications like Excel or Google Docs, preserving all original structures including tables, lists, formatting, and more.
Snapshot
 Snapshot copies the selection area into the clipboard as a image.
Snapshot copies the selection area into the clipboard as a image.


